
What is neural network in python ?
What’s a Neural Network?
Most introductory texts to Neural Networks brings up brain analogies when describing them. Without delving into brain analogies, I find it easier to simply describe Neural Networks as a mathematical function that maps a given input to a desired output.
We have introduced the basic ideas about neuronal networks in the previous chapter of our tutorial.
We pointed out the similarity between neurons and neural networks in biology. We also introduced very small articial neural networks and introduced decision boundaries and the XOR problem.
Neural Network Theory
A neural network is a supervised learning algorithm which means that we provide it the input data containing the independent variables and the output data that contains the dependent variable. For instance, in our example our independent variables are smoking, obesity and exercise. The dependent variable is whether a person is diabetic or not.
In the beginning, the neural network makes some random predictions, these predictions are matched with the correct output and the error or the difference between the predicted values and the actual values is calculated. The function that finds the difference between the actual value and the propagated values is called the cost function. The cost here refers to the error. Our objective is to minimize the cost function. Training a neural network basically refers to minimizing the cost function. We will see how we can perform this task.
Neural networks are the core of deep learning, a field which has practical applications in many different areas. Today neural networks are used for image classification, speech recognition, object detection etc. Now, Let’s try to understand the basic unit behind all this state of art technique.
A single neuron transforms given input into some output. Depending on the given input and weights assigned to each input, decide whether the neuron fired or not. Let’s assume the neuron has 3 input connections and one output.
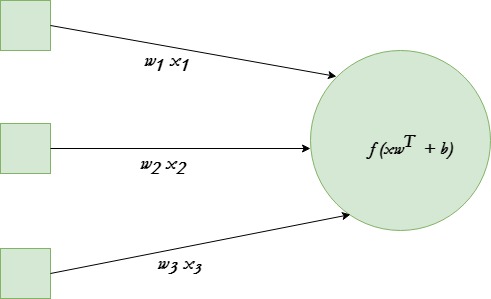
We will be using tanh activation function in given example.
The end goal is to find the optimal set of weights for this neuron which produces correct results. Do this by training the neuron with several different training examples. At each step calculate the error in the output of neuron, and back propagate the gradients. The step of calculating the output of neuron is called forward propagation while calculation of gradients is called back propagation.
Neural Network Implementation in Python
Let's first create our feature set and the corresponding labels. Execute the following script:
import numpy as np
feature_set = np.array([[0,1,0],[0,0,1],[1,0,0],[1,1,0],[1,1,1]])
labels = np.array([[1,0,0,1,1]])
labels = labels.reshape(5,1)
In the above script, we create our feature set. It contains five records. Similarly, we created a labelsset which contains corresponding labels for each record in the feature set. The labels are the answers we're trying to predict with the neural network.
The next step is to define hyper parameters for our neural network. Execute the following script to do so:
np.random.seed(42)
weights = np.random.rand(3,1)
bias = np.random.rand(1)
lr = 0.05
In the script above we used the random.seed function so that we can get the same random values whenever the script is executed.
In the next step, we initialize our weights with normally distributed random numbers. Since we have three features in the input, we have a vector of three weights. We then initialize the bias value with another random number. Finally, we set the learning rate to 0.05.
Next, we need to define our activation function and its derivative (I'll explain in a moment why we need to find the derivative of the activation). Our activation function is the sigmoid function, which we covered earlier.
All machine Learning beginners and enthusiasts need some hands-on experience with Python, especially with creating neural networks. This tutorial aims to equip anyone with zero experience in coding to understand and create an Artificial Neural network in Python, provided you have the basic understanding of how an ANN works.
Prerequisites
-
Basic understanding of Artificial Neural Network
-
Basic understanding of python language
Before dipping your hands in the code jar be aware that we will not be using any specific dataset with the aim to generalize the concept. The codes can be used as templates for creating simple neural networks that can get you started with Machine Learning.
Feedforward
As we’ve seen in the sequential graph above, feedforward is just simple calculus and for a basic 2-layer neural network, the output of the Neural Network is:
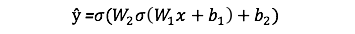
Let’s add a feedforward function in our python code to do exactly that. Note that for simplicity, we have assumed the biases to be 0.
However, we still need a way to evaluate the “goodness” of our predictions (i.e. how far off are our predictions)? The Loss Function allows us to do exactly that.
Loss Function
There are many available loss functions, and the nature of our problem should dictate our choice of loss function. In this tutorial, we’ll use a simple sum-of-sqaures error as our loss function.
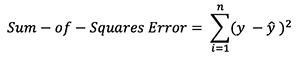
That is, the sum-of-squares error is simply the sum of the difference between each predicted value and the actual value. The difference is squared so that we measure the absolute value of the difference.